deepseek本地部署流程(解决服务器繁忙以及隐私等
前文
由于官网deepseek老是出问题
所以我决定本地部署deepseek
很简单,不需要有什么特殊技能
正文开始
Ollama
首先到这个ollama的官网
goto-Ollama
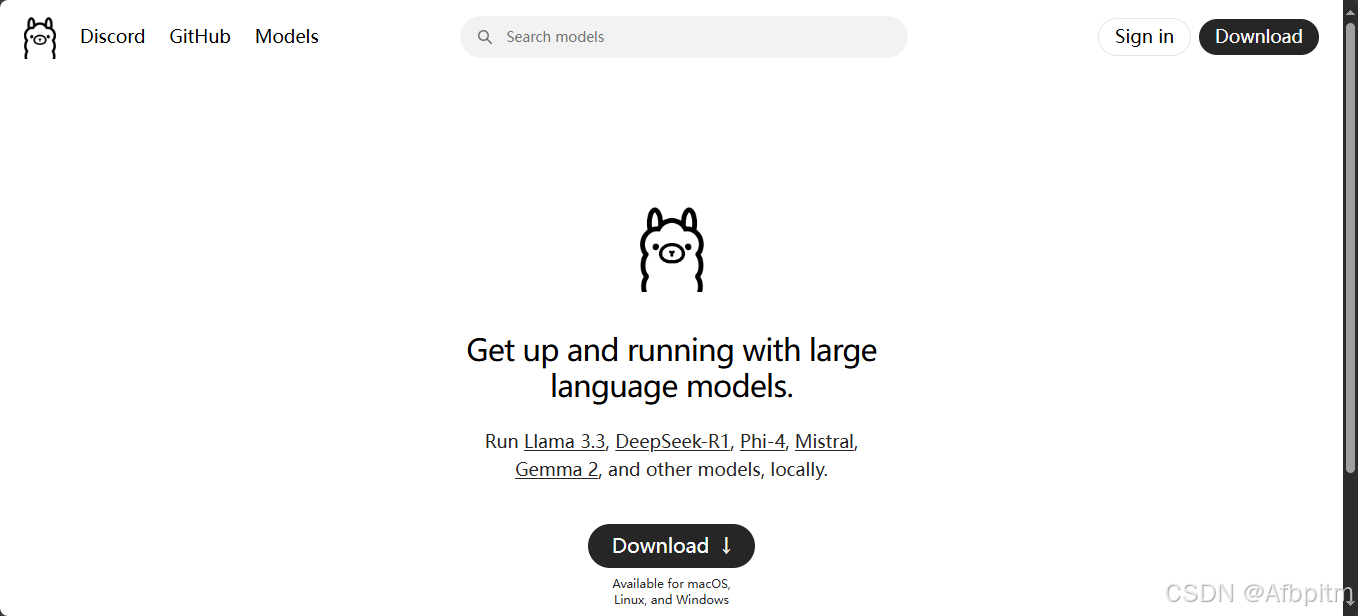
然后点击中间这个大大的Download
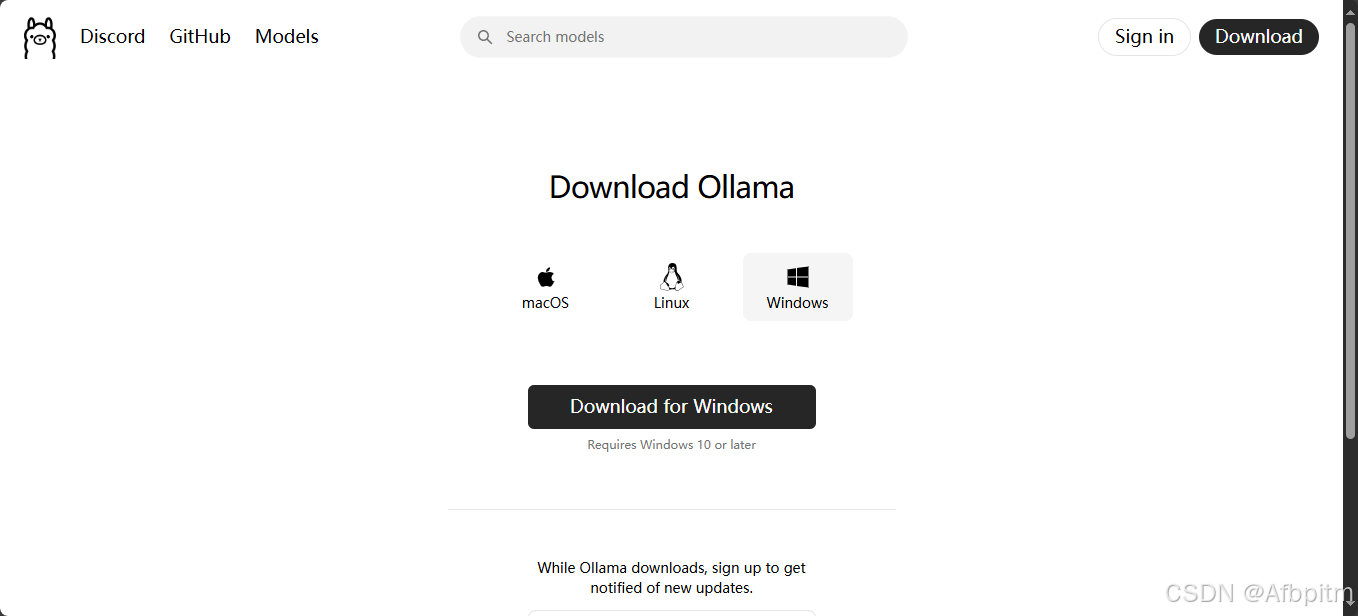
然后再次点击中间这个大大的Download for Windows
等待下载完成
下载完成
完成后去自己的下载目录文件夹里找下载好的文件,双击打开
点击Install
等待安装完成
安装完成


安装完成后查看任务栏向上小箭头
羊驼图标就是ollama的进程
然后进行下一步(不要关ollama进程)
ChatBoxAI
打开它的官网
goto-ChatBoxAI
然后点击这个免费下载 (for Windows)
下载开始,等待下载完成
下载完成
打开自己下载文件夹
双击打开下载好的文件
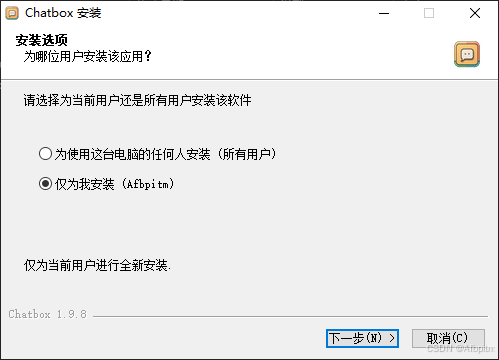
下一步
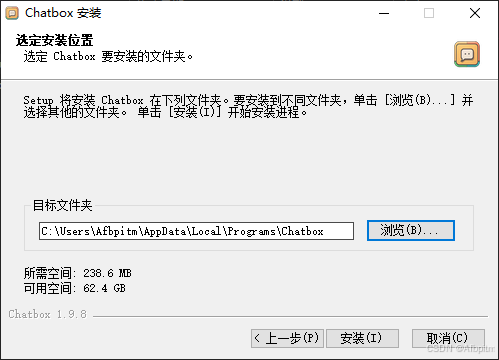
选个安装位置,点浏览
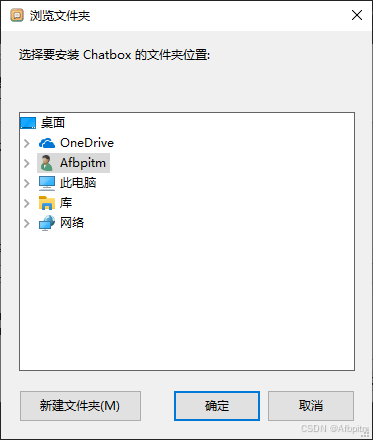
然后就会打开这个
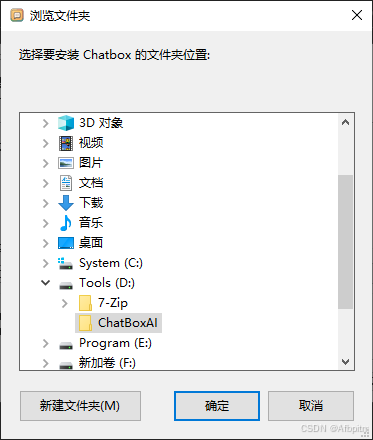
在里面找好自己的目录,点确定
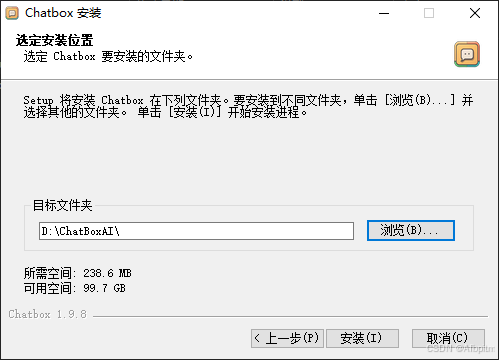
就会跳回这个界面,点安装
等待安装完成
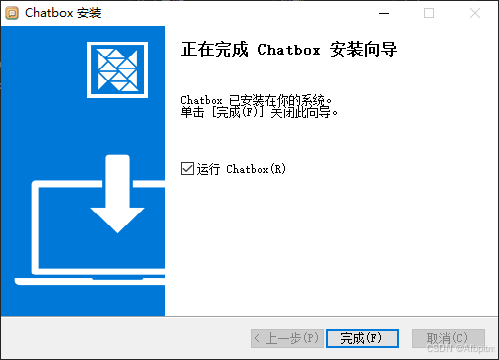
安装完成后,点完成,稍等一会
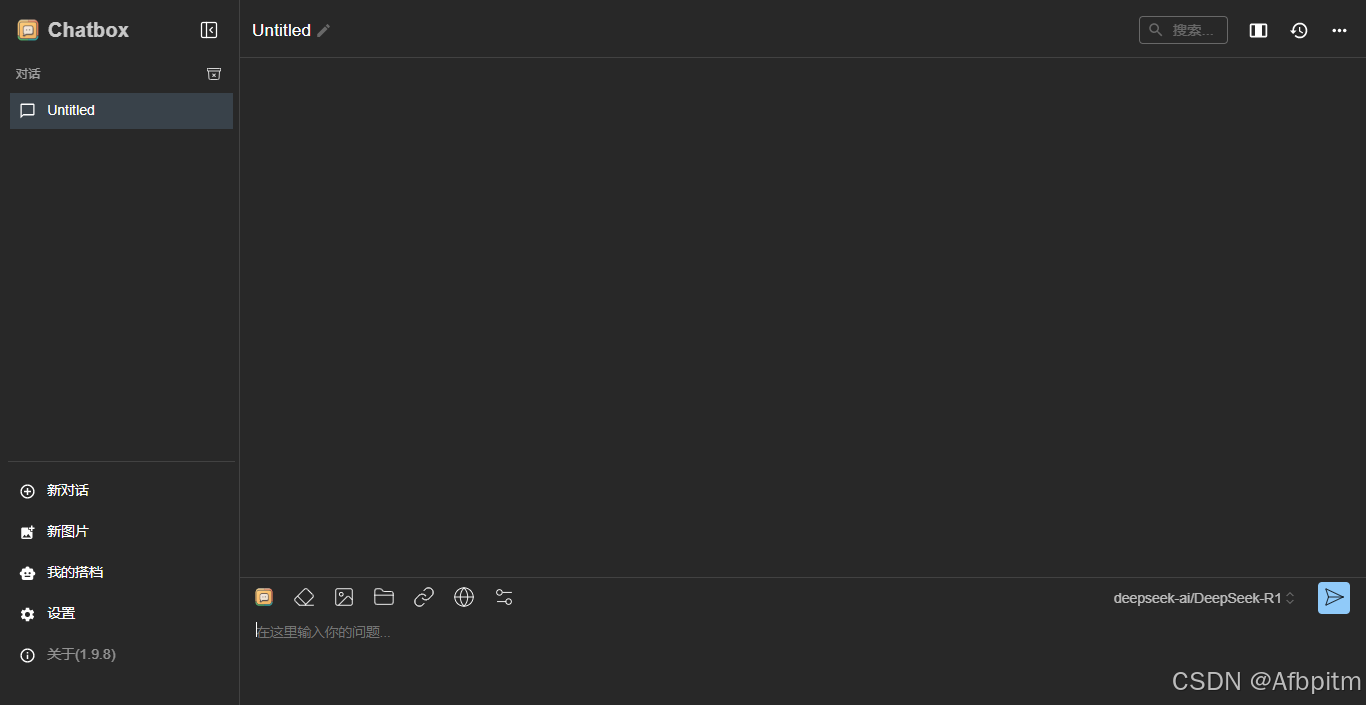
就会出现这个界面(这就是以后跟deepseek对话的地方),关了它进行下一步骤
DeepSeek-R1
拉取模型需要在命令行里操作
同时按下Win+R启动运行命令窗口
输入cmd
回车
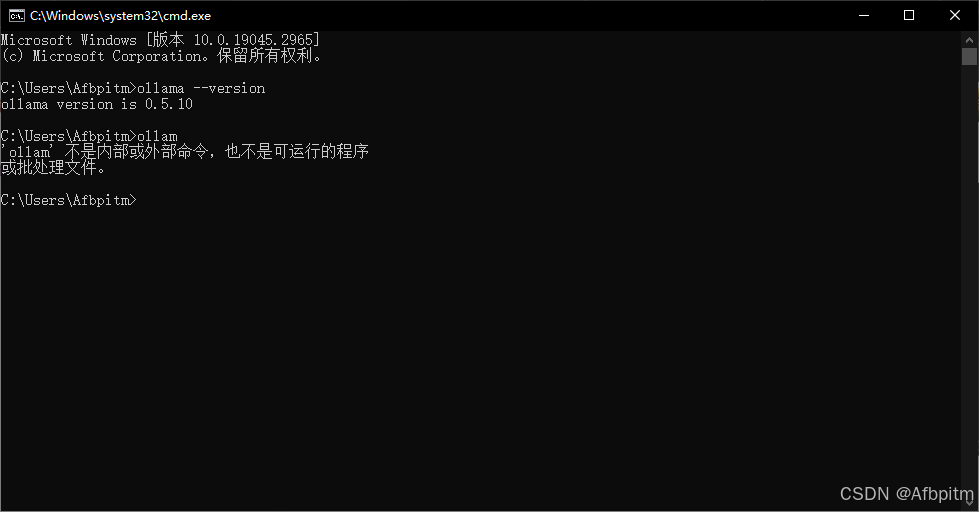
出现这个(命令提示符)窗口,然后输入以下命令
ollama --version
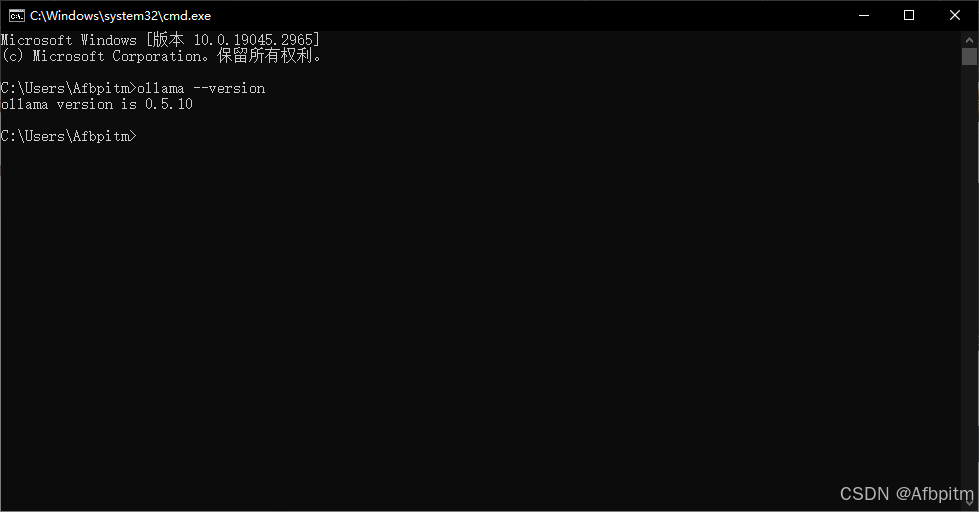
然后就会出现如上提示
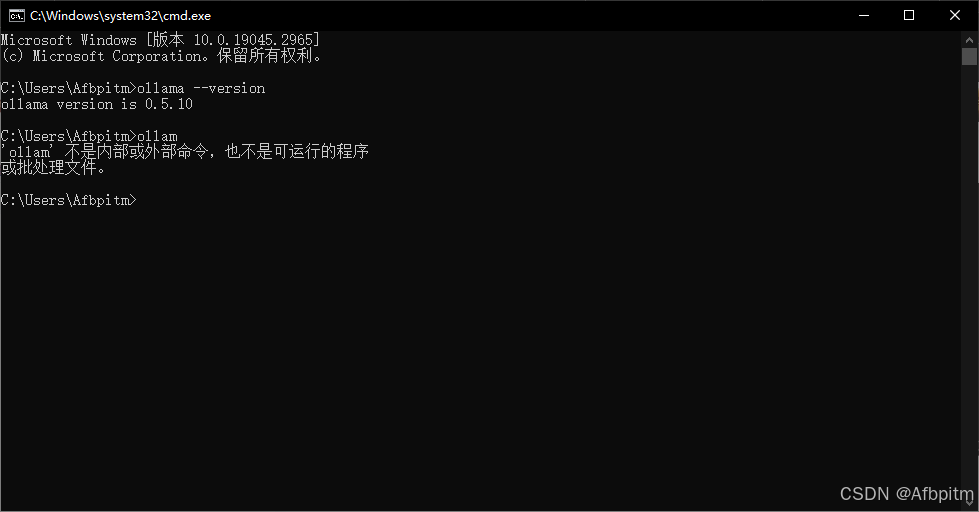
如果是这样的,那就说明你没输对命令,如果反复检查是输对了,那你只能回到Ollama章节把那一章的内容重来一遍了
goto-Ollama
然后再次回到Ollama的官网(不要关闭命令提示符)
点击Models(左上角)
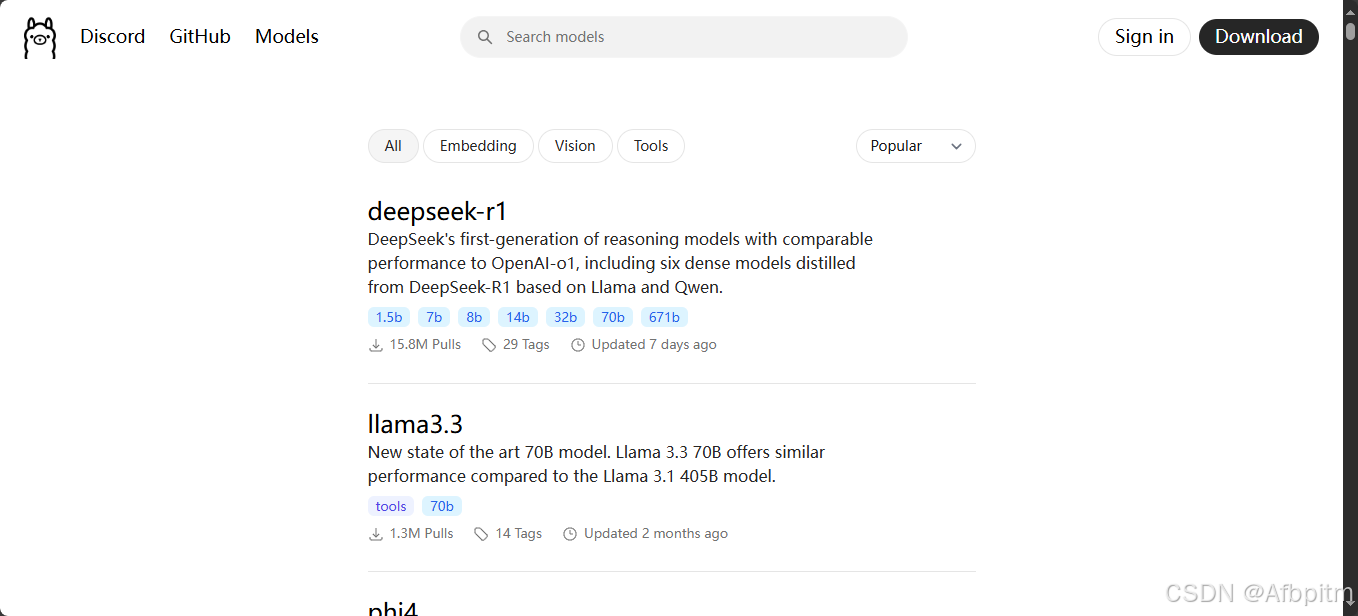
然后自己选自己的AI,一般就是第一个显示的那个AI-deepseek-r1
点击deepseek-r1
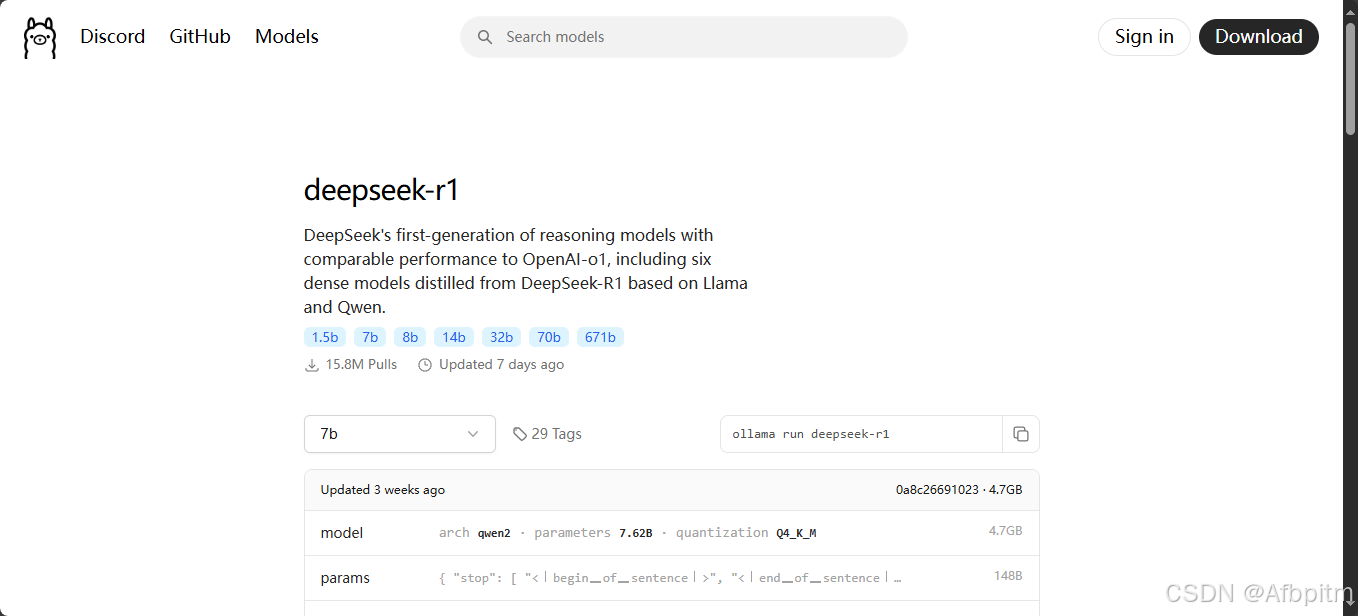
点击下拉框选择适合自己的蒸馏版
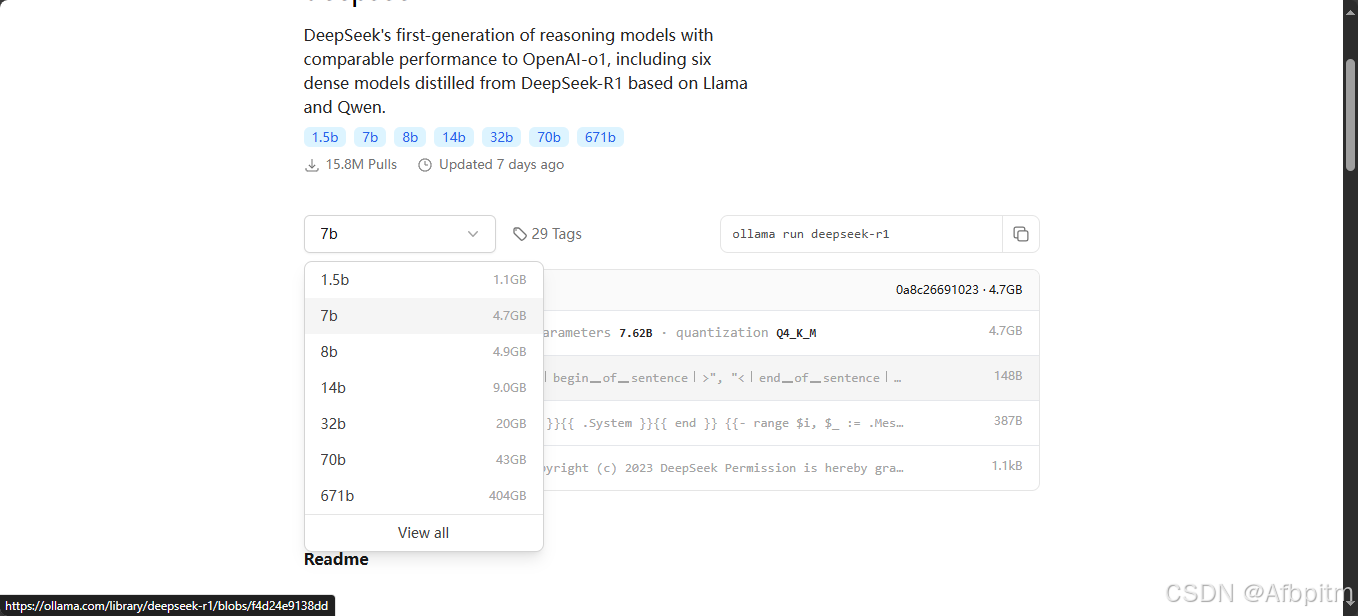
选择哪个呢,在Decide章节,自行阅读后选择
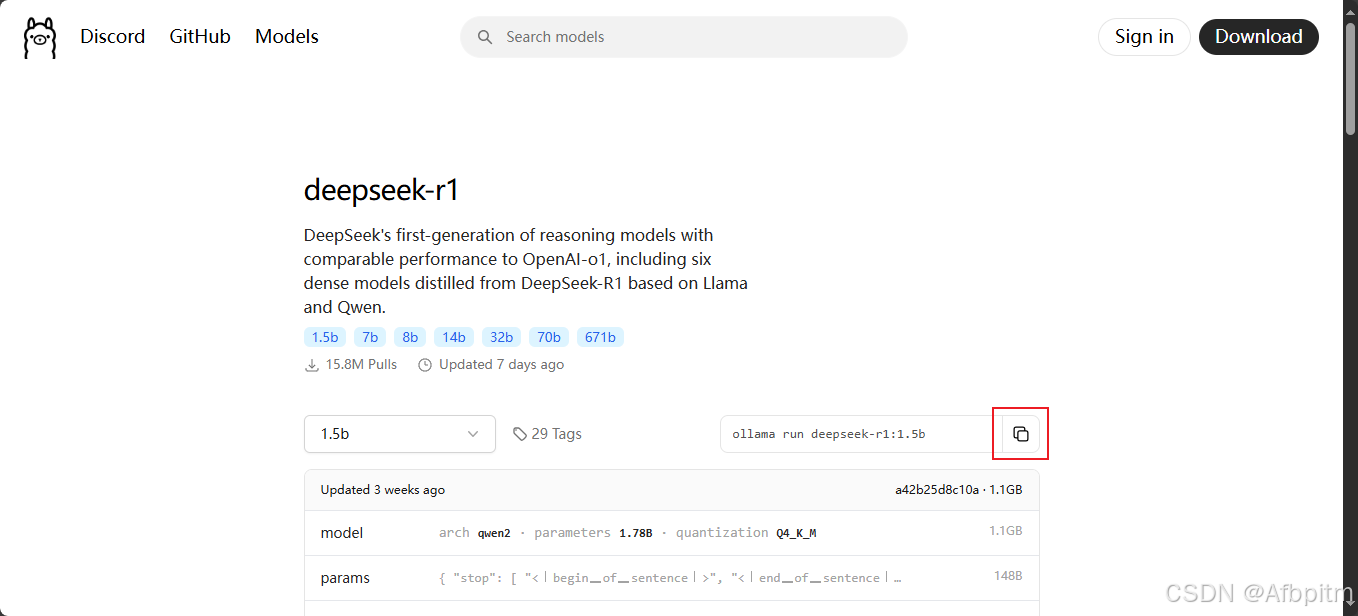
选好之后点击上图红框中的copy按钮
回到命令提示符中,点击右键复制内容
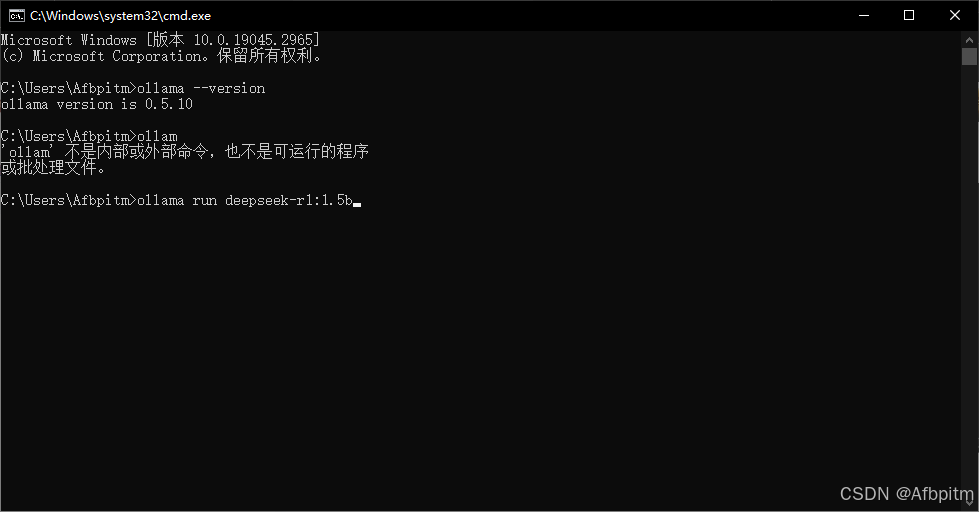
好了之后回车
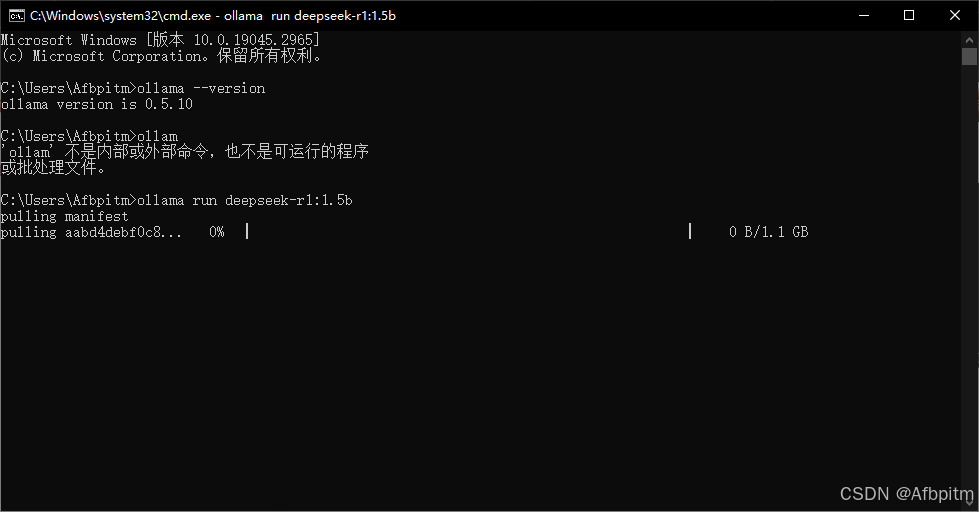
等待拉取模型
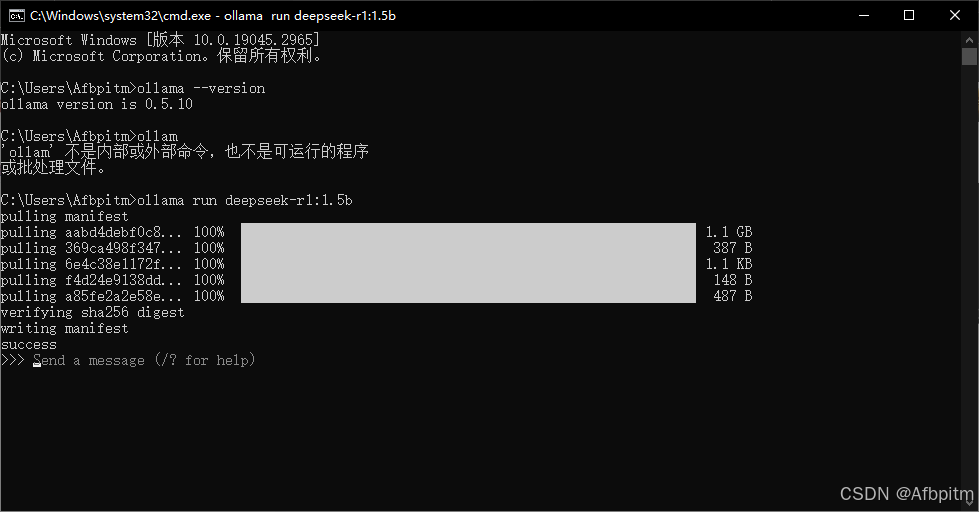
模型拉取成功(这里的success表示成功)
然后在命令行里会出现Send a message字样,然后不用管它了
下一步
组装

打开桌面上的ChatBoxAI
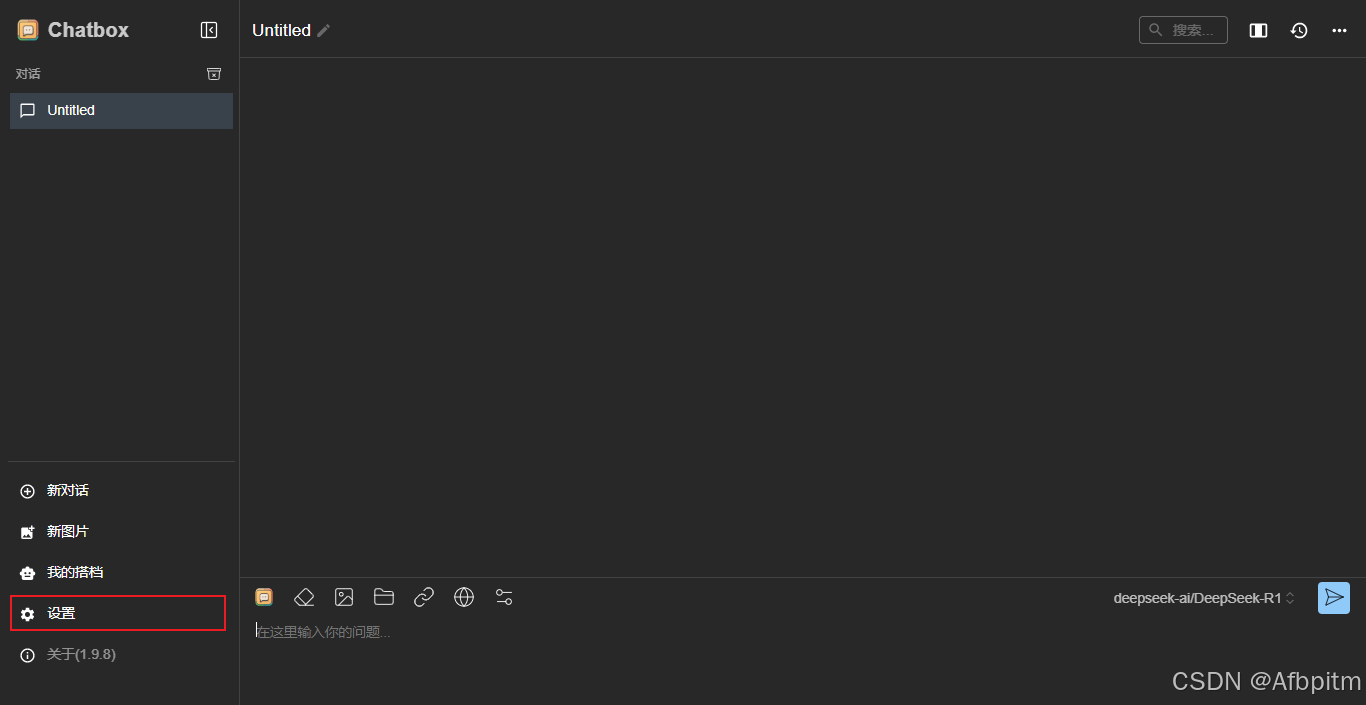
点击设置
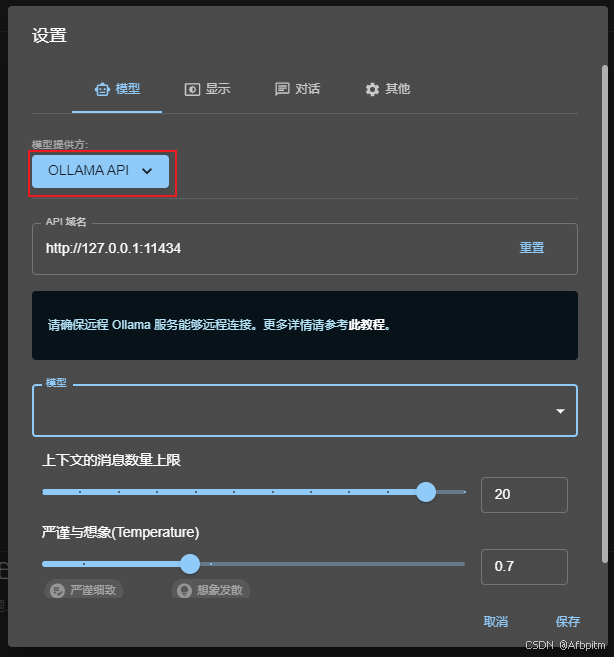
打开模型提供方下拉框
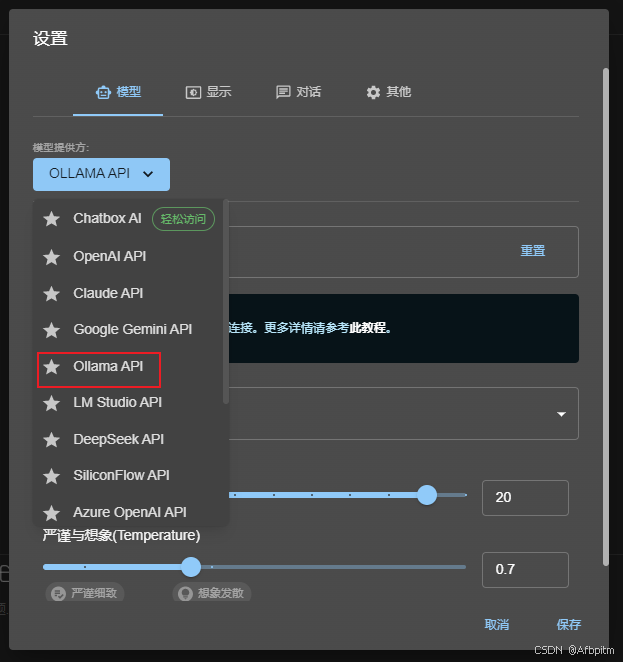
选择上图红框中这个Ollama API
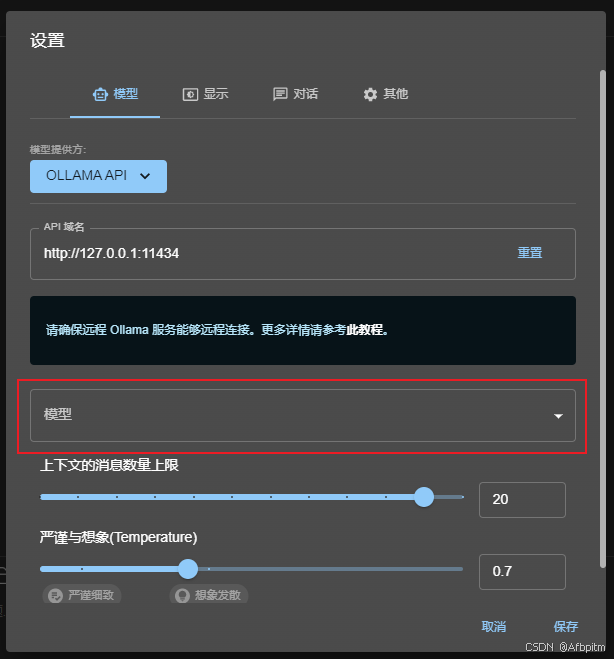
打开模型下拉框
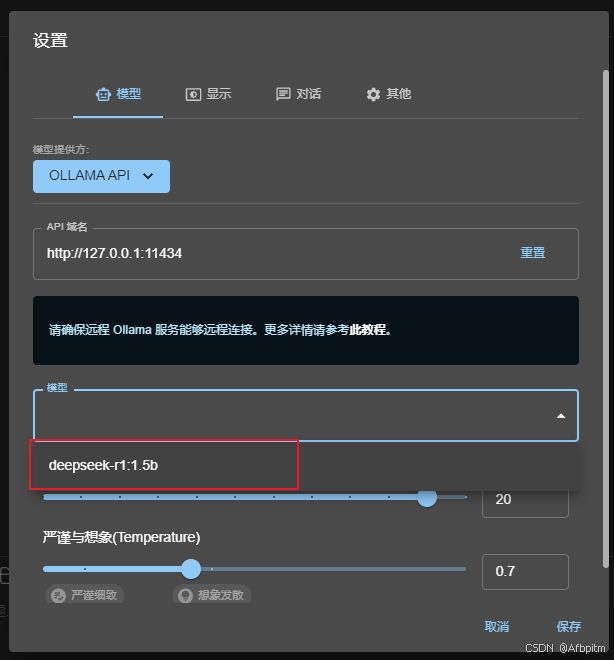
可以看到这里有我们刚刚拉取的deepseek,选择它
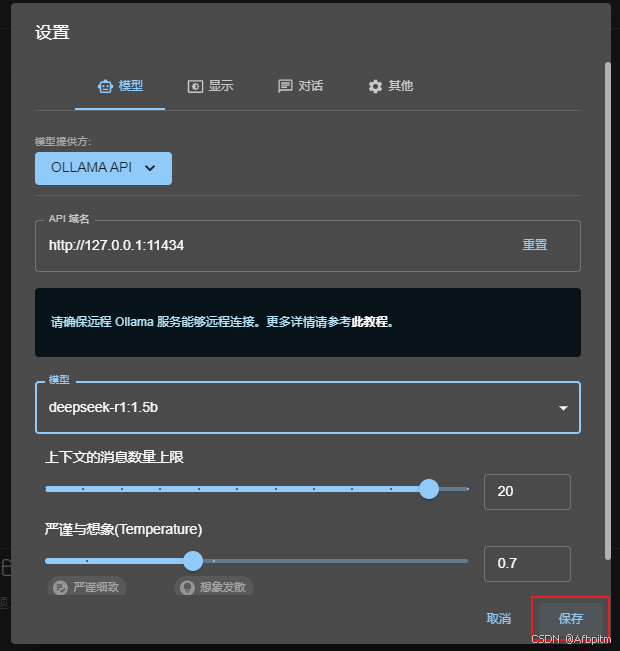
保存
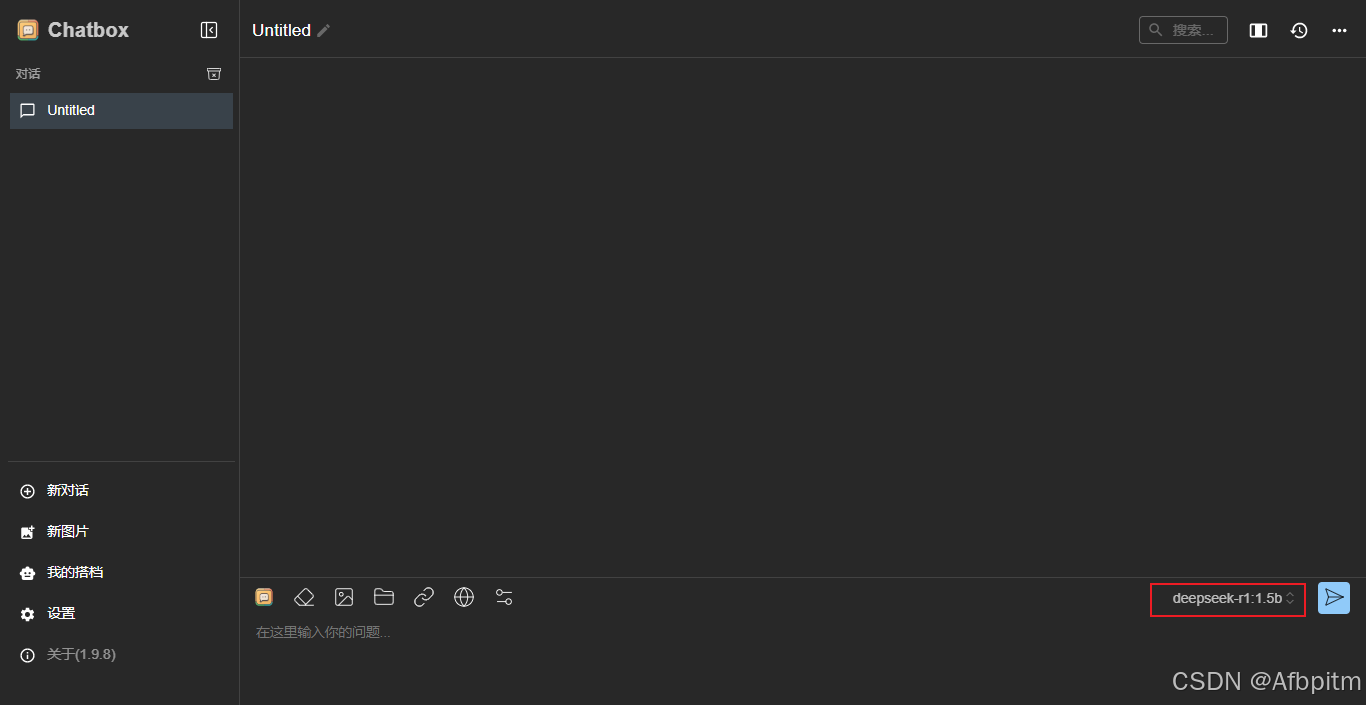
这里也变成自己刚刚拉取的AI了
然后输入一个试试
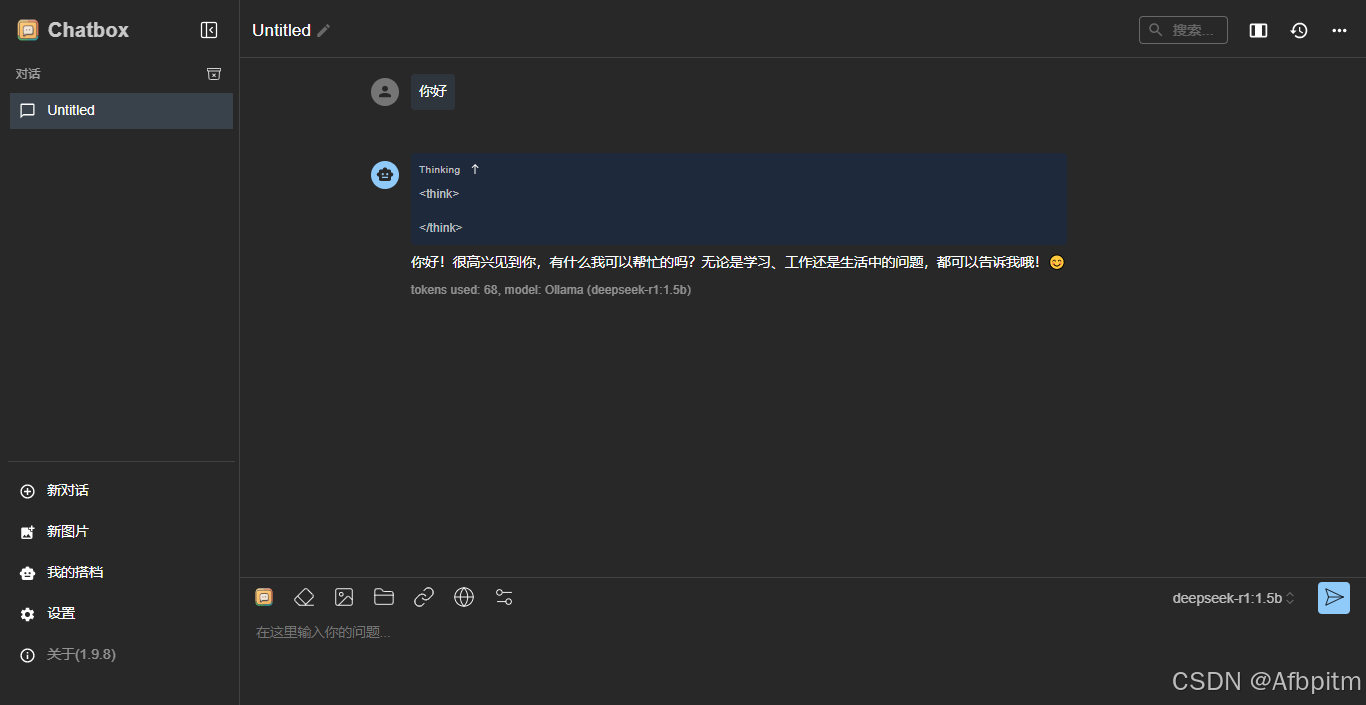
以后自己打开ChatBoxAI就可以开始对话了
关闭会自己杀死AI进程
Decide
- CPU: 至少 8 核,推荐 16 核或以上。
- GPU: 至少 16GB 显存,推荐 24GB 或以上(如 NVIDIA RTX 3090、A100 等)。
- 内存: 至少 32GB,推荐 64GB 或以上。
- 存储: 至少 100GB SSD,推荐 NVMe SSD 以加快加载速度。
- 小型蒸馏版: 适合低资源环境,显存需求约 8GB,内存需求约 16GB。(1.5b、7b、8b)
- 中型蒸馏版: 显存需求约 16GB,内存需求约 32GB。(14b)
- 大型蒸馏版: 显存需求约 24GB,内存需求约 64GB。(32b)
- 需求配置更高的蒸馏版不推荐个人拉取本地部署使用
- 实际配置可以更低,不过可能会降低配置根据配置自己选择即可
- 好了,至此就完成了deepseek的本地部署了
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。