Redis和数据库的一致性(Canal+MQ) 的实现
想要保证缓存与数据库的双写一致,一共有4种方式,即4种同步策略:
- 先更新缓存,再更新数据库;
- 先更新数据库,再更新缓存;
- 先删除缓存,再更新数据库;
- 先更新数据库,再删除缓存
首先说好结论,这4种同步策略无论是哪一种,都无法保证数据库和redis的强一致性,只能保证最终一致性,如要保证强一致,那么只能通过加锁来实现,那么就会造成性能问题,即CAP理论中的AP(强一致)和CP(高可用性)进行取舍,绝大多数场景是确保高可用(CP)。
更新缓存还是删除缓存
下面,我们来分析一下,应该采用更新缓存还是删除缓存的方式。
1、更新缓存
优点:每次数据变化都及时更新缓存,所以查询时不容易出现未命中的情况。
缺点:更新缓存的消耗比较大。如果数据需要经过复杂的计算再写入缓存,那么频繁的更新缓存,就会影响服务器的性能。如果是写入数据频繁的业务场景,那么可能频繁的更新缓存时,却没有业务读取该数据。
2、删除缓存
优点:操作简单,无论更新操作是否复杂,都是将缓存中的数据直接删除。
缺点:删除缓存后,下一次查询缓存会出现未命中,这时需要重新读取一次数据库。从上面的比较来看,一般情况下,删除缓存是更优的方案。
先操作数据库还是更新缓存
1.先更新数据库再删除缓存
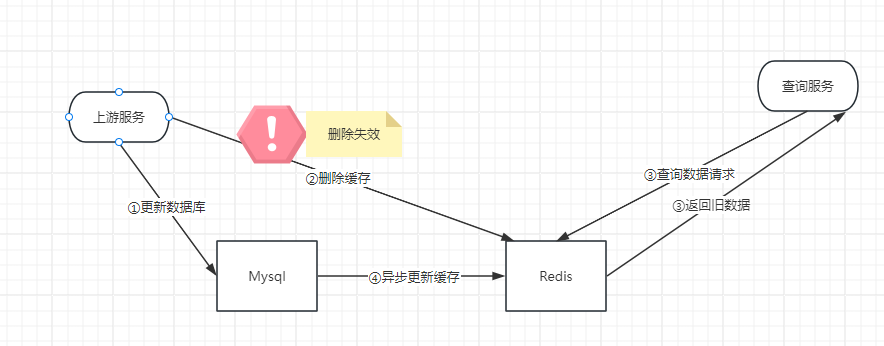
- 线程A更新数据库成功,线程A删除缓存失败;
- 线程B读取缓存成功,由于缓存删除失败,所以线程B读取到的是缓存中旧的数据。
- 最后线程A删除缓存成功,有别的线程访问缓存同样的数据,与数据库中的数据是一样。
- 最终,缓存和数据库的数据是一致的,但是会有一些线程读到旧的数据。
1.2正常情况下没有出现失败场景
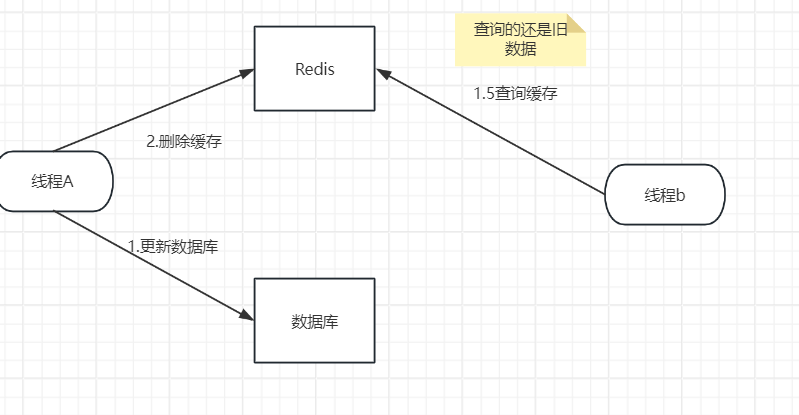
在并发场景下,也许会有些许线程像线程b一样读的是旧数据,但在删除缓存后,最终缓存与数据库的数据是一致的,并且都是最新的数据。但线程B在这个过程里读到了旧的数据,可能还有其他线程也像线程B一样,在这两步之间读到了缓存中旧的数据,但因为这两步的执行速度会比较快,所以影响不大。对于这两步之后,其他进程再读取缓存数据的时候,就不会出现类似于进程B的问题了。
2.先删除缓存再更新数据库
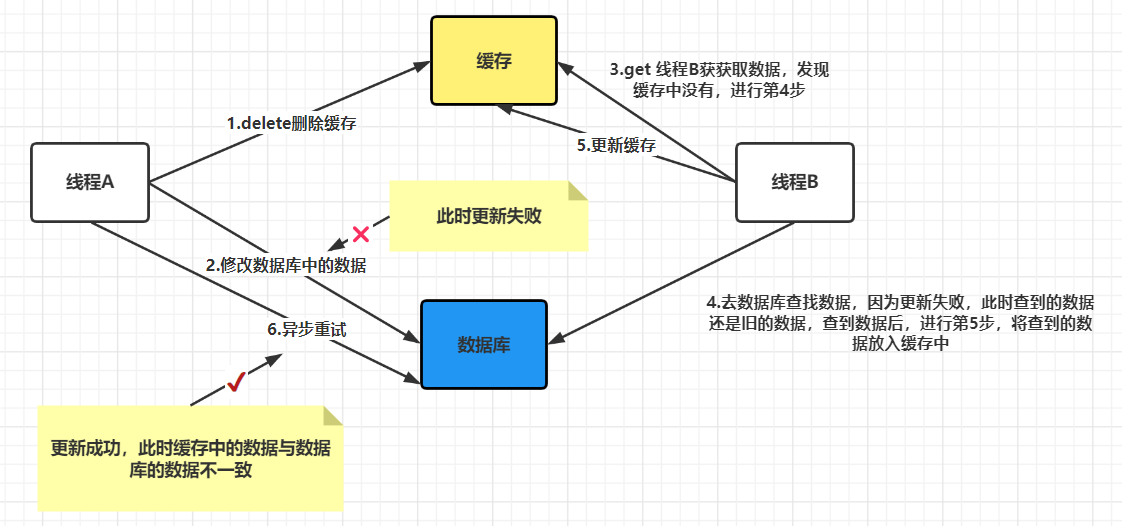
- 线程A删除缓存成功,线程A更新数据库失败;
- 线程B从缓存中读取数据;由于缓存被删,进程B无法从缓存中得到数据,进而从数据库读取数据;此时数据库中的数据更新失败,线程B从数据库成功获取旧的数据,然后将数据更新到了缓存。
- 最终,如果没有异步重试的话缓存和数据库的数据是一致的,但仍然是旧的数据。
2.2正常情况下没有出现失败场景
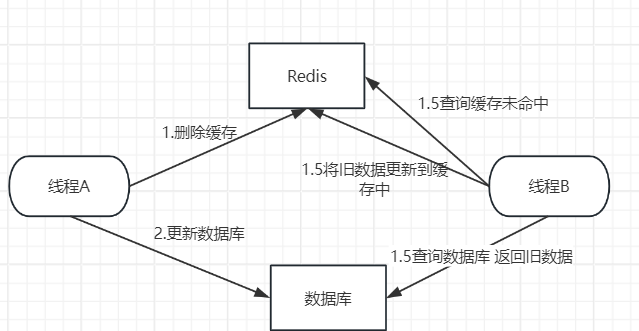
进程A的两步操作均成功,但由于存在并发,在这两步之间,进程B访问了缓存。最终结果是,缓存中存储了旧的数据,而数据库中存储了新的数据,二者数据不一致。
这种方式的解决方案也就是在第2步更新数据库后,延迟一会再删一次Redis,也就是延迟双删,这样就可以保证最终数据一致性。
最终结论:
经过对比你会发现,先更新数据库、再删除缓存是影响更小的方案。如果第二步出现失败的情况,则可以采用重试机制解决问题。
最终解决方案
利用(MQ)消息队列和Canal中间件进行删除的补偿
Canal目前在大型企业中热度下降,使用flinkcdc是目前的趋势,而目前主流CDC(变更数据获取)是flink cdc 而flinkcdc插件是基于flink平台(大数据平台)此处只需要简单理解Canal作用并简单实现即可。目前企业中常见的数据同步方案就是CDC中间件+MQ的方案,大型公司一般是有大数据业务,所以使用大数据平台和kafka,此处使用的是Canal+Rabbitmq
Canal安装与部署
Mysql前置准备
在服务中找到Mysql配置文件对应目录
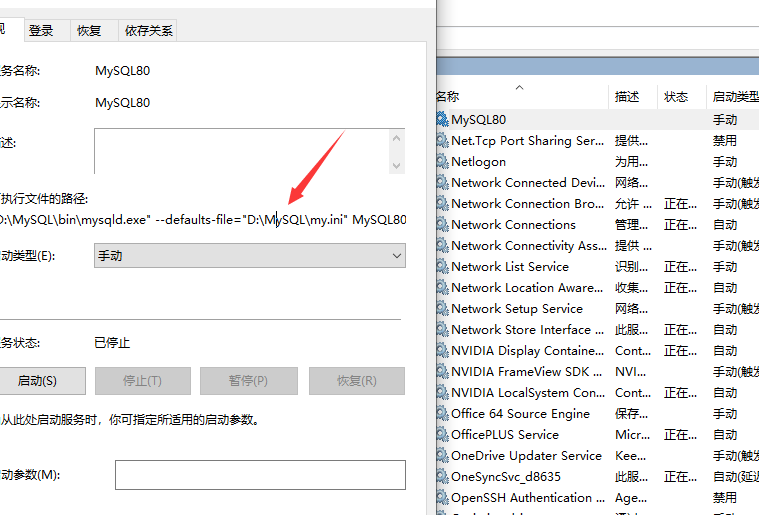
其中一共需要注意四个配置项
server-id=1 #master端的ID号【必须是唯一的】; log-bin=D:\MySQL\binlog\mysql-bin.log #同步的日志路径,一定注意这个目录要是mysql有权限写入的 binlog_format=row #行级,记录每次操作后每行记录的变化。 binlog-do-db=db_xiaomi #指定库,缩小监控的范围。
1.查看端口号配置对应主要用于集群环境下区分id
2.创建binlog文件存放目录
3.数据的保存格式(一共有三种)
4.指定需要监控的库名(如果该项不指定配置,那么默认所有数据库开启binlog)
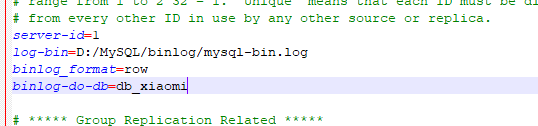
设置好后启动服务。
启动后看到在binlog文件目录中看到log文件
